Evals
Evals is shorthand for both AI system Evaluation as a broad topic and for specific Evaluation Metrics or Evaluators as individual tests. Ironically, the overloading of this term makes it difficult to evaluate what people are even talking about when they say "Evals" (without further context).
Warning
Unlike unit tests, evals are an emerging art/science; anyone who claims to know exactly how your evals should be defined can safely be ignored.
Pydantic Evals Package
Pydantic Evals is a powerful evaluation framework designed to help you systematically test and evaluate the performance and accuracy of the systems you build, from augmented LLMs to multi-agent systems.
Install Pydantic Evals as part of the Pydantic AI (agent framework) package, or stand-alone.
We've designed Pydantic Evals to be useful while not being too opinionated since we (along with everyone else) are still figuring out best practices. We'd love your feedback on the package and how we can improve it.
In Beta
Pydantic Evals support was introduced in v0.0.47 and is currently in beta. The API is subject to change and the documentation is incomplete.
Code-First Evaluation
Pydantic Evals follows a code-first approach where you define all evaluation components (datasets, experiments, tasks, cases and evaluators) in Python code. This differs from platforms with fully web-based configuration.
When you run an Experiment you'll see results appear wherever you run your python code (IDE, terminal, etc) - send this data to any notebook or application for further visualisation and analysis.
If you are using Pydantic Logfire, your experiment results automatically appear in the Logfire web interface for visualization, comparison, and collaborative analysis. Logfire serves as a read-only observability layer - you write and run evals in code, then view and analyze results in the web UI.
Installation
To install the Pydantic Evals package, run:
pip install pydantic-evals
uv add pydantic-evals
pydantic-evals does not depend on pydantic-ai, but has an optional dependency on logfire if you'd like to
use OpenTelemetry traces in your evals, or send evaluation results to logfire.
pip install 'pydantic-evals[logfire]'
uv add 'pydantic-evals[logfire]'
Pydantic Evals Data Model
Data Model Diagram
Dataset (1) ──────────── (Many) Case
│ │
│ │
└─── (Many) Experiment ──┴─── (Many) Case results
│
└─── (1) Task
│
└─── (Many) Evaluator
Key Relationships
- Dataset → Cases: One Dataset contains many Cases (composition)
- Dataset → Experiments: One Dataset can be used in many Experiments over time (aggregation)
- Experiment → Case results: One Experiment generates results by executing each Case
- Experiment → Task: One Experiment evaluates one defined Task
- Experiment → Evaluators: One Experiment uses multiple Evaluators (dataset-level + case-specific)
- Case results → Evaluators: Individual Case results are scored by both dataset-level evaluators and case-specific evaluators (if they exist)
Data Flow
- Dataset creation: Define case templates and evaluators in YAML/JSON
- Experiment execution: Run
dataset.evaluate_sync(task_function) - Cases run: Each Case is executed against the Task
- Evaluation: Evaluators score the Task outputs for each Case
- Results: Experiment collects all Case results and returns a summary report
A metaphor
A useful metaphor (although not perfect) is to think of evals like a Unit Testing framework:
-
Cases + Evaluators are your individual unit tests - each one defines a specific scenario you want to test, complete with inputs and expected outcomes. Just like a unit test, a case asks: "Given this input, does my system produce the right output?"
-
Datasets are like test suites - they are the scaffolding that holds your unit tests together. They group related cases and define shared evaluation criteria that should apply across all tests in the suite.
-
Experiments are like running your entire test suite and getting a coverage report. When you execute
dataset.evaluate_sync(my_ai_function), you're running all your cases against your AI system and collecting the results - just like runningpytestand getting a summary of passes, failures, and performance metrics.
The key difference from traditional unit testing is that AI systems are probabilistic. If you're type checking you'll still get a simple pass/fail, but scores for text outputs are likely qualitative and/or categorical, and more open to interpretation. Keep in mind that unlike unit test coverage reports, we are looking at model behavior over the probabilistic space of user inputs, not coverage of source code.
Datasets and Cases
In Pydantic Evals, everything begins with Datasets and Cases:
Case: A single test scenario corresponding to Task inputs. Can also optionally have a name, expected outputs, metadata, and evaluators.Dataset: A collection of test Cases designed for the evaluation of a specific task or function.
from pydantic_evals import Case, Dataset
case1 = Case(
name='simple_case',
inputs='What is the capital of France?',
expected_output='Paris',
metadata={'difficulty': 'easy'},
)
dataset = Dataset(cases=[case1])
(This example is complete, it can be run "as is")
Evaluators
Evaluators analyze and score the results of your Task when tested against a Case.
These can be a classic unit test: deterministic, code-based checks, such as testing model output format with a regex, or checking for the appearance of PII or sensitive data. Alternatively Evaluators can assess the non-deterministic model outputs for qualities like accuracy, precision/recall, hallucinations or instruction-following.
While both kinds of testing are necessary and useful in LLM systems, classical code-based tests are cheaper and easier than tests which require either human or machine review of model outputs. We encourage you to look for quick wins of this type, when setting up a test framework for your system.
Pydantic Evals includes several built-in evaluators and allows you to define custom evaluators:
from dataclasses import dataclass
from pydantic_evals.evaluators import Evaluator, EvaluatorContext
from pydantic_evals.evaluators.common import IsInstance
from simple_eval_dataset import dataset
dataset.add_evaluator(IsInstance(type_name='str')) # (1)!
@dataclass
class MyEvaluator(Evaluator):
async def evaluate(self, ctx: EvaluatorContext[str, str]) -> float: # (2)!
if ctx.output == ctx.expected_output:
return 1.0
elif (
isinstance(ctx.output, str)
and ctx.expected_output.lower() in ctx.output.lower()
):
return 0.8
else:
return 0.0
dataset.add_evaluator(MyEvaluator())
- You can add built-in evaluators to a dataset using the
add_evaluatormethod. - This custom evaluator returns a simple score based on whether the output matches the expected output.
(This example is complete, it can be run "as is")
Run your Experiment
This involves running a task against all cases in a dataset:
Putting the above two examples together and using the more declarative evaluators kwarg to Dataset:
from pydantic_evals import Case, Dataset
from pydantic_evals.evaluators import Evaluator, EvaluatorContext, IsInstance
case1 = Case( # (1)!
name='simple_case',
inputs='What is the capital of France?',
expected_output='Paris',
metadata={'difficulty': 'easy'},
)
class MyEvaluator(Evaluator[str, str]):
def evaluate(self, ctx: EvaluatorContext[str, str]) -> float:
if ctx.output == ctx.expected_output:
return 1.0
elif (
isinstance(ctx.output, str)
and ctx.expected_output.lower() in ctx.output.lower()
):
return 0.8
else:
return 0.0
dataset = Dataset(
cases=[case1],
evaluators=[IsInstance(type_name='str'), MyEvaluator()], # (3)!
)
async def guess_city(question: str) -> str: # (4)!
return 'Paris'
report = dataset.evaluate_sync(guess_city) # (5)!
report.print(include_input=True, include_output=True, include_durations=False) # (6)!
"""
Evaluation Summary: guess_city
┏━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓
┃ Case ID ┃ Inputs ┃ Outputs ┃ Scores ┃ Assertions ┃
┡━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩
│ simple_case │ What is the capital of France? │ Paris │ MyEvaluator: 1.00 │ ✔ │
├─────────────┼────────────────────────────────┼─────────┼───────────────────┼────────────┤
│ Averages │ │ │ MyEvaluator: 1.00 │ 100.0% ✔ │
└─────────────┴────────────────────────────────┴─────────┴───────────────────┴────────────┘
"""
- Create a test case as above
- Also create a custom evaluator function as above
- Create a
Datasetwith test cases, also set theevaluatorswhen creating the dataset - Our function to evaluate.
- Run the evaluation with
evaluate_sync, which runs the function against all test cases in the dataset, and returns anEvaluationReportobject. - Print the report with
print, which shows the results of the evaluation, including input and output. We have omitted duration here just to keep the printed output from changing from run to run.
(This example is complete, it can be run "as is")
Evaluation with LLMJudge
In this example we evaluate a method for generating recipes based on customer orders.
from __future__ import annotations
from typing import Any
from pydantic import BaseModel
from pydantic_ai import Agent, format_as_xml
from pydantic_evals import Case, Dataset
from pydantic_evals.evaluators import IsInstance, LLMJudge
class CustomerOrder(BaseModel): # (1)!
dish_name: str
dietary_restriction: str | None = None
class Recipe(BaseModel):
ingredients: list[str]
steps: list[str]
recipe_agent = Agent(
'groq:llama-3.3-70b-versatile',
output_type=Recipe,
system_prompt=(
'Generate a recipe to cook the dish that meets the dietary restrictions.'
),
)
async def transform_recipe(customer_order: CustomerOrder) -> Recipe: # (2)!
r = await recipe_agent.run(format_as_xml(customer_order))
return r.output
recipe_dataset = Dataset[CustomerOrder, Recipe, Any]( # (3)!
cases=[
Case(
name='vegetarian_recipe',
inputs=CustomerOrder(
dish_name='Spaghetti Bolognese', dietary_restriction='vegetarian'
),
expected_output=None, # (4)
metadata={'focus': 'vegetarian'},
evaluators=(
LLMJudge( # (5)!
rubric='Recipe should not contain meat or animal products',
),
),
),
Case(
name='gluten_free_recipe',
inputs=CustomerOrder(
dish_name='Chocolate Cake', dietary_restriction='gluten-free'
),
expected_output=None,
metadata={'focus': 'gluten-free'},
# Case-specific evaluator with a focused rubric
evaluators=(
LLMJudge(
rubric='Recipe should not contain gluten or wheat products',
),
),
),
],
evaluators=[ # (6)!
IsInstance(type_name='Recipe'),
LLMJudge(
rubric='Recipe should have clear steps and relevant ingredients',
include_input=True,
model='anthropic:claude-3-7-sonnet-latest', # (7)!
),
],
)
report = recipe_dataset.evaluate_sync(transform_recipe)
print(report)
"""
Evaluation Summary: transform_recipe
┏━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━┓
┃ Case ID ┃ Assertions ┃ Duration ┃
┡━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━┩
│ vegetarian_recipe │ ✔✔✔ │ 10ms │
├────────────────────┼────────────┼──────────┤
│ gluten_free_recipe │ ✔✔✔ │ 10ms │
├────────────────────┼────────────┼──────────┤
│ Averages │ 100.0% ✔ │ 10ms │
└────────────────────┴────────────┴──────────┘
"""
- Define models for our task — Input for recipe generation task and output of the task.
- Define our recipe generation function - this is the task we want to evaluate.
- Create a dataset with different test cases and different rubrics.
- No expected output, we'll let the LLM judge the quality.
- Case-specific evaluator with a focused rubric using
LLMJudge. - Dataset-level evaluators that apply to all cases, including a general quality rubric for all recipes
- By default
LLMJudgeusesopenai:gpt-4o, here we use a specific Anthropic model.
(This example is complete, it can be run "as is")
Saving and Loading Datasets
Datasets can be saved to and loaded from YAML or JSON files.
from pathlib import Path
from judge_recipes import CustomerOrder, Recipe, recipe_dataset
from pydantic_evals import Dataset
recipe_transforms_file = Path('recipe_transform_tests.yaml')
recipe_dataset.to_file(recipe_transforms_file) # (1)!
print(recipe_transforms_file.read_text())
"""
# yaml-language-server: $schema=recipe_transform_tests_schema.json
cases:
- name: vegetarian_recipe
inputs:
dish_name: Spaghetti Bolognese
dietary_restriction: vegetarian
metadata:
focus: vegetarian
evaluators:
- LLMJudge: Recipe should not contain meat or animal products
- name: gluten_free_recipe
inputs:
dish_name: Chocolate Cake
dietary_restriction: gluten-free
metadata:
focus: gluten-free
evaluators:
- LLMJudge: Recipe should not contain gluten or wheat products
evaluators:
- IsInstance: Recipe
- LLMJudge:
rubric: Recipe should have clear steps and relevant ingredients
model: anthropic:claude-3-7-sonnet-latest
include_input: true
"""
# Load dataset from file
loaded_dataset = Dataset[CustomerOrder, Recipe, dict].from_file(recipe_transforms_file)
print(f'Loaded dataset with {len(loaded_dataset.cases)} cases')
#> Loaded dataset with 2 cases
(This example is complete, it can be run "as is")
Parallel Evaluation
You can control concurrency during evaluation (this might be useful to prevent exceeding a rate limit):
import asyncio
import time
from pydantic_evals import Case, Dataset
# Create a dataset with multiple test cases
dataset = Dataset(
cases=[
Case(
name=f'case_{i}',
inputs=i,
expected_output=i * 2,
)
for i in range(5)
]
)
async def double_number(input_value: int) -> int:
"""Function that simulates work by sleeping for a tenth of a second before returning double the input."""
await asyncio.sleep(0.1) # Simulate work
return input_value * 2
# Run evaluation with unlimited concurrency
t0 = time.time()
report_default = dataset.evaluate_sync(double_number)
print(f'Evaluation took less than 0.5s: {time.time() - t0 < 0.5}')
#> Evaluation took less than 0.5s: True
report_default.print(include_input=True, include_output=True, include_durations=False) # (1)!
"""
Evaluation Summary:
double_number
┏━━━━━━━━━━┳━━━━━━━━┳━━━━━━━━━┓
┃ Case ID ┃ Inputs ┃ Outputs ┃
┡━━━━━━━━━━╇━━━━━━━━╇━━━━━━━━━┩
│ case_0 │ 0 │ 0 │
├──────────┼────────┼─────────┤
│ case_1 │ 1 │ 2 │
├──────────┼────────┼─────────┤
│ case_2 │ 2 │ 4 │
├──────────┼────────┼─────────┤
│ case_3 │ 3 │ 6 │
├──────────┼────────┼─────────┤
│ case_4 │ 4 │ 8 │
├──────────┼────────┼─────────┤
│ Averages │ │ │
└──────────┴────────┴─────────┘
"""
# Run evaluation with limited concurrency
t0 = time.time()
report_limited = dataset.evaluate_sync(double_number, max_concurrency=1)
print(f'Evaluation took more than 0.5s: {time.time() - t0 > 0.5}')
#> Evaluation took more than 0.5s: True
report_limited.print(include_input=True, include_output=True, include_durations=False) # (2)!
"""
Evaluation Summary:
double_number
┏━━━━━━━━━━┳━━━━━━━━┳━━━━━━━━━┓
┃ Case ID ┃ Inputs ┃ Outputs ┃
┡━━━━━━━━━━╇━━━━━━━━╇━━━━━━━━━┩
│ case_0 │ 0 │ 0 │
├──────────┼────────┼─────────┤
│ case_1 │ 1 │ 2 │
├──────────┼────────┼─────────┤
│ case_2 │ 2 │ 4 │
├──────────┼────────┼─────────┤
│ case_3 │ 3 │ 6 │
├──────────┼────────┼─────────┤
│ case_4 │ 4 │ 8 │
├──────────┼────────┼─────────┤
│ Averages │ │ │
└──────────┴────────┴─────────┘
"""
- We have omitted duration here just to keep the printed output from changing from run to run.
- We have omitted duration here just to keep the printed output from changing from run to run.
(This example is complete, it can be run "as is")
OpenTelemetry Integration
Pydantic Evals integrates with OpenTelemetry for tracing.
The EvaluatorContext includes a property called span_tree
which returns a SpanTree. The SpanTree provides a way to query and analyze
the spans generated during function execution. This provides a way to access the results of instrumentation during
evaluation.
Note
If you just want to write unit tests that ensure that specific spans are produced during calls to your evaluation
task, it's usually better to just use the logfire.testing.capfire fixture directly.
There are two main ways this is useful.
import asyncio
from typing import Any
import logfire
from pydantic_evals import Case, Dataset
from pydantic_evals.evaluators import Evaluator
from pydantic_evals.evaluators.context import EvaluatorContext
from pydantic_evals.otel.span_tree import SpanQuery
logfire.configure( # ensure that an OpenTelemetry tracer is configured
send_to_logfire='if-token-present'
)
class SpanTracingEvaluator(Evaluator[str, str]):
"""Evaluator that analyzes the span tree generated during function execution."""
def evaluate(self, ctx: EvaluatorContext[str, str]) -> dict[str, Any]:
# Get the span tree from the context
span_tree = ctx.span_tree
if span_tree is None:
return {'has_spans': False, 'performance_score': 0.0}
# Find all spans with "processing" in the name
processing_spans = span_tree.find(lambda node: 'processing' in node.name)
# Calculate total processing time
total_processing_time = sum(
(span.duration.total_seconds() for span in processing_spans), 0.0
)
# Check for error spans
error_query: SpanQuery = {'name_contains': 'error'}
has_errors = span_tree.any(error_query)
# Calculate a performance score (lower is better)
performance_score = 1.0 if total_processing_time < 1.0 else 0.5
return {
'has_spans': True,
'has_errors': has_errors,
'performance_score': 0 if has_errors else performance_score,
}
async def process_text(text: str) -> str:
"""Function that processes text with OpenTelemetry instrumentation."""
with logfire.span('process_text'):
# Simulate initial processing
with logfire.span('text_processing'):
await asyncio.sleep(0.1)
processed = text.strip().lower()
# Simulate additional processing
with logfire.span('additional_processing'):
if 'error' in processed:
with logfire.span('error_handling'):
logfire.error(f'Error detected in text: {text}')
return f'Error processing: {text}'
await asyncio.sleep(0.2)
processed = processed.replace(' ', '_')
return f'Processed: {processed}'
# Create test cases
dataset = Dataset(
cases=[
Case(
name='normal_text',
inputs='Hello World',
expected_output='Processed: hello_world',
),
Case(
name='text_with_error',
inputs='Contains error marker',
expected_output='Error processing: Contains error marker',
),
],
evaluators=[SpanTracingEvaluator()],
)
# Run evaluation - spans are automatically captured since logfire is configured
report = dataset.evaluate_sync(process_text)
# Print the report
report.print(include_input=True, include_output=True, include_durations=False) # (1)!
"""
Evaluation Summary: process_text
┏━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓
┃ Case ID ┃ Inputs ┃ Outputs ┃ Scores ┃ Assertions ┃
┡━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩
│ normal_text │ Hello World │ Processed: hello_world │ performance_score: 1.00 │ ✔✗ │
├─────────────────┼───────────────────────┼─────────────────────────────────────────┼──────────────────────────┼────────────┤
│ text_with_error │ Contains error marker │ Error processing: Contains error marker │ performance_score: 0 │ ✔✔ │
├─────────────────┼───────────────────────┼─────────────────────────────────────────┼──────────────────────────┼────────────┤
│ Averages │ │ │ performance_score: 0.500 │ 75.0% ✔ │
└─────────────────┴───────────────────────┴─────────────────────────────────────────┴──────────────────────────┴────────────┘
"""
- We have omitted duration here just to keep the printed output from changing from run to run.
(This example is complete, it can be run "as is")
Generating Test Datasets
Pydantic Evals allows you to generate test datasets using LLMs with generate_dataset.
Datasets can be generated in either JSON or YAML format, in both cases a JSON schema file is generated alongside the dataset and referenced in the dataset, so you should get type checking and auto-completion in your editor.
from __future__ import annotations
from pathlib import Path
from pydantic import BaseModel, Field
from pydantic_evals import Dataset
from pydantic_evals.generation import generate_dataset
class QuestionInputs(BaseModel, use_attribute_docstrings=True): # (1)!
"""Model for question inputs."""
question: str
"""A question to answer"""
context: str | None = None
"""Optional context for the question"""
class AnswerOutput(BaseModel, use_attribute_docstrings=True): # (2)!
"""Model for expected answer outputs."""
answer: str
"""The answer to the question"""
confidence: float = Field(ge=0, le=1)
"""Confidence level (0-1)"""
class MetadataType(BaseModel, use_attribute_docstrings=True): # (3)!
"""Metadata model for test cases."""
difficulty: str
"""Difficulty level (easy, medium, hard)"""
category: str
"""Question category"""
async def main():
dataset = await generate_dataset( # (4)!
dataset_type=Dataset[QuestionInputs, AnswerOutput, MetadataType],
n_examples=2,
extra_instructions="""
Generate question-answer pairs about world capitals and landmarks.
Make sure to include both easy and challenging questions.
""",
)
output_file = Path('questions_cases.yaml')
dataset.to_file(output_file) # (5)!
print(output_file.read_text())
"""
# yaml-language-server: $schema=questions_cases_schema.json
cases:
- name: Easy Capital Question
inputs:
question: What is the capital of France?
metadata:
difficulty: easy
category: Geography
expected_output:
answer: Paris
confidence: 0.95
evaluators:
- EqualsExpected
- name: Challenging Landmark Question
inputs:
question: Which world-famous landmark is located on the banks of the Seine River?
metadata:
difficulty: hard
category: Landmarks
expected_output:
answer: Eiffel Tower
confidence: 0.9
evaluators:
- EqualsExpected
"""
- Define the schema for the inputs to the task.
- Define the schema for the expected outputs of the task.
- Define the schema for the metadata of the test cases.
- Call
generate_datasetto create aDatasetwith 2 cases confirming to the schema. - Save the dataset to a YAML file, this will also write
questions_cases_schema.jsonwith the schema JSON schema forquestions_cases.yamlto make editing easier. The magicyaml-language-servercomment is supported by at least vscode, jetbrains/pycharm (more details here).
(This example is complete, it can be run "as is" — you'll need to add asyncio.run(main(answer)) to run main)
You can also write datasets as JSON files:
from pathlib import Path
from pydantic_evals import Dataset
from pydantic_evals.generation import generate_dataset
from generate_dataset_example import AnswerOutput, MetadataType, QuestionInputs
async def main():
dataset = await generate_dataset( # (1)!
dataset_type=Dataset[QuestionInputs, AnswerOutput, MetadataType],
n_examples=2,
extra_instructions="""
Generate question-answer pairs about world capitals and landmarks.
Make sure to include both easy and challenging questions.
""",
)
output_file = Path('questions_cases.json')
dataset.to_file(output_file) # (2)!
print(output_file.read_text())
"""
{
"$schema": "questions_cases_schema.json",
"cases": [
{
"name": "Easy Capital Question",
"inputs": {
"question": "What is the capital of France?"
},
"metadata": {
"difficulty": "easy",
"category": "Geography"
},
"expected_output": {
"answer": "Paris",
"confidence": 0.95
},
"evaluators": [
"EqualsExpected"
]
},
{
"name": "Challenging Landmark Question",
"inputs": {
"question": "Which world-famous landmark is located on the banks of the Seine River?"
},
"metadata": {
"difficulty": "hard",
"category": "Landmarks"
},
"expected_output": {
"answer": "Eiffel Tower",
"confidence": 0.9
},
"evaluators": [
"EqualsExpected"
]
}
]
}
"""
- Generate the
Datasetexactly as above. - Save the dataset to a JSON file, this will also write
questions_cases_schema.jsonwith th JSON schema forquestions_cases.json. This time the$schemakey is included in the JSON file to define the schema for IDEs to use while you edit the file, there's no formal spec for this, but it works in vscode and pycharm and is discussed at length in json-schema-org/json-schema-spec#828.
(This example is complete, it can be run "as is" — you'll need to add asyncio.run(main(answer)) to run main)
Integration with Logfire
Pydantic Evals is implemented using OpenTelemetry to record traces of the evaluation process. These traces contain all the information included in the terminal output as attributes, but also include full tracing from the executions of the evaluation task function.
You can send these traces to any OpenTelemetry-compatible backend, including Pydantic Logfire.
All you need to do is configure Logfire via logfire.configure:
import logfire
from judge_recipes import recipe_dataset, transform_recipe
logfire.configure(
send_to_logfire='if-token-present', # (1)!
environment='development', # (2)!
service_name='evals', # (3)!
)
recipe_dataset.evaluate_sync(transform_recipe)
- The
send_to_logfireargument controls when traces are sent to Logfire. You can set it to'if-token-present'to send data to Logfire only if theLOGFIRE_TOKENenvironment variable is set. See the Logfire configuration docs for more details. - The
environmentargument sets the environment for the traces. It's a good idea to set this to'development'when running tests or evaluations and sending data to a project with production data, to make it easier to filter these traces out while reviewing data from your production environment(s). - The
service_nameargument sets the service name for the traces. This is displayed in the Logfire UI to help you identify the source of the associated spans.
Logfire has some special integration with Pydantic Evals traces, including a table view of the evaluation results
on the evaluation root span (which is generated in each call to Dataset.evaluate):
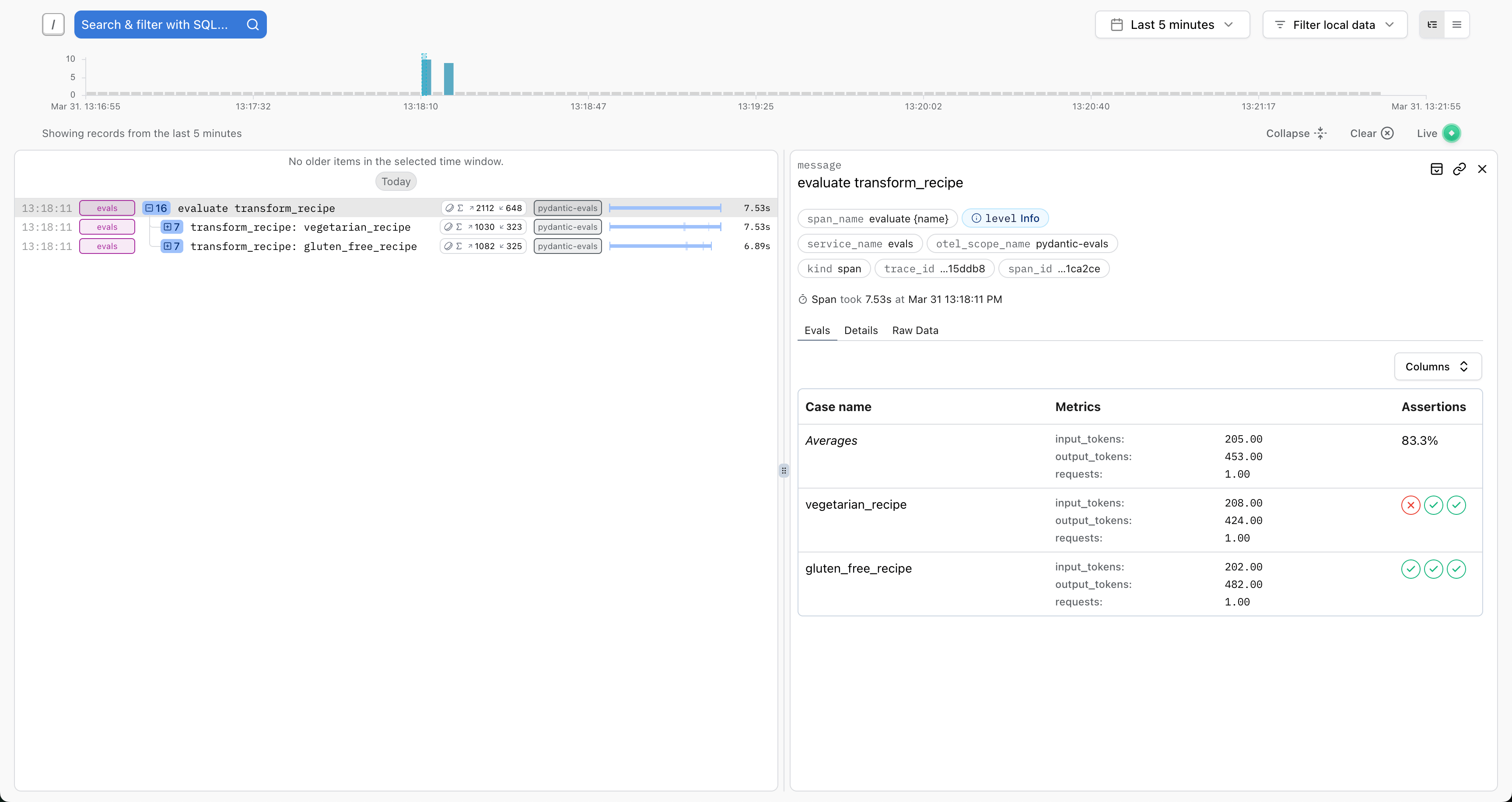
and a detailed view of the inputs and outputs for the execution of each case:
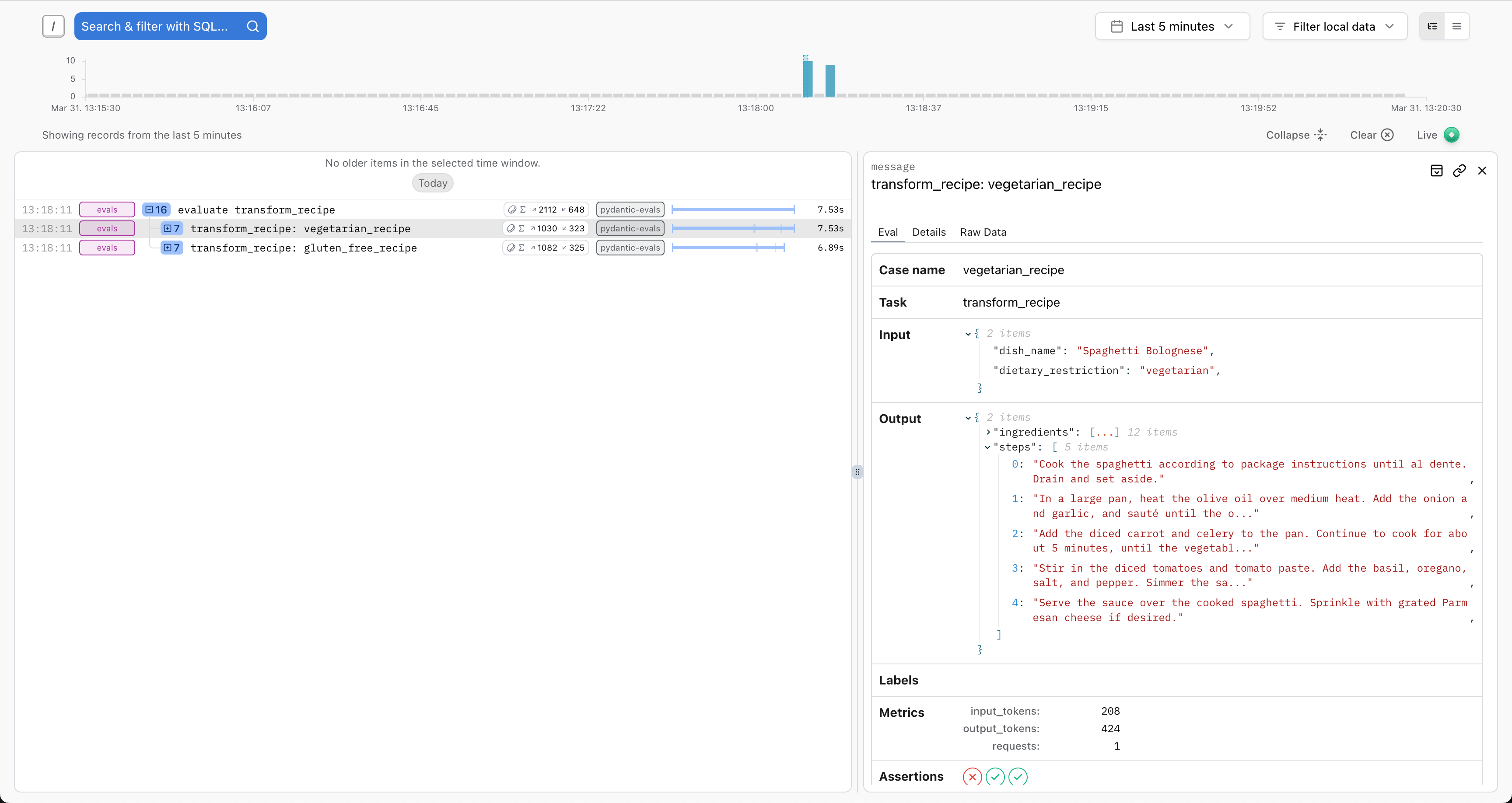
In addition, any OpenTelemetry spans generated during the evaluation process will be sent to Logfire, allowing you to visualize the full execution of the code called during the evaluation process:
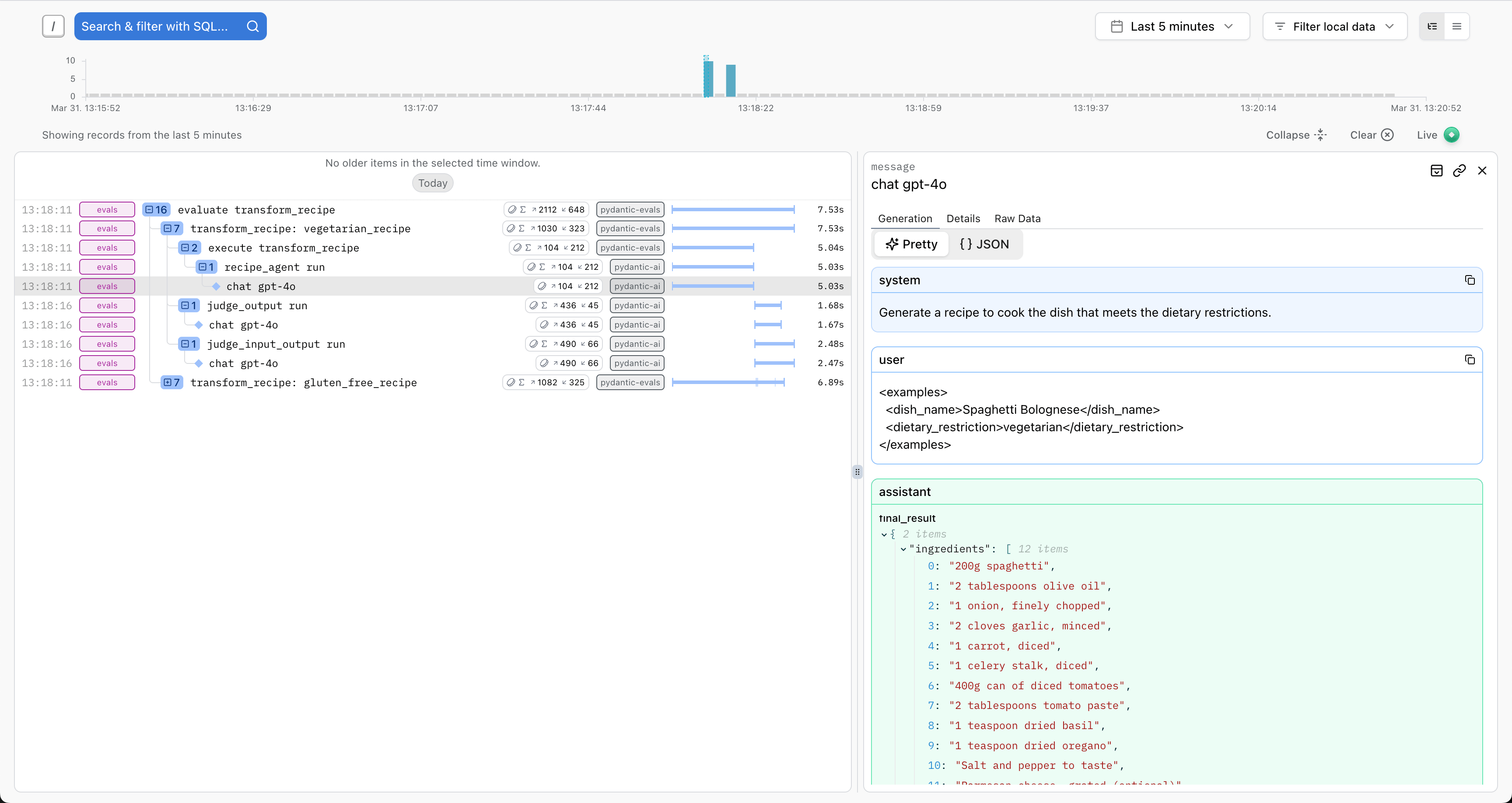
This can be especially helpful when attempting to write evaluators that make use of the span_tree property of the
EvaluatorContext, as described in the
OpenTelemetry Integration section above.
This allows you to write evaluations that depend on information about which code paths were executed during the call to the task function without needing to manually instrument the code being evaluated, as long as the code being evaluated is already adequately instrumented with OpenTelemetry. In the case of Pydantic AI agents, for example, this can be used to ensure specific tools are (or are not) called during the execution of specific cases.
Using OpenTelemetry in this way also means that all data used to evaluate the task executions will be accessible in the traces produced by production runs of the code, making it straightforward to perform the same evaluations on production data.
API Reference
For comprehensive coverage of all classes, methods, and configuration options, see the detailed API Reference documentation.
Next Steps
- Start with simple evaluations using basic evaluators like
IsInstanceandEqualsExpected - Integrate with Logfire to visualize results and enable team collaboration
- Build comprehensive test suites with diverse cases covering edge cases and performance requirements
- Implement custom evaluators for domain-specific quality metrics
- Automate evaluation runs as part of your development and deployment pipeline